
Java Web Crawler:基于浏览器的方法

Vladimir Ikryanov
2021 年 5 月 26 日

现在互联网上有很多数据。 通常,需要对其进行提取和分析以用于各种营销研究和业务决策目的。 当需要时,应该快速有效地完成。
为什么需要收集和分析数据? 出于多种原因可能有必要:
- 进行网站审核;
- 聚合来自在线商店的数据;
- 神经网络训练集准备;
- 监控社交网络、新闻源、博客中的评论;
- 分析网站内容,例如识别网站上的死链接等。
数据不仅限于文本; 它可以是图像、视频、表格、各种文件等。可能需要提取链接和文本、按关键字或短语搜索、收集图片等。
另一项重要任务是监控网站的健康状况,检查是否没有死链接以及网站是否普遍可用。
所有这些都需要现成的工具。
现有解决方案
收集和分析数据的最常见方法是向 Web 服务器发送请求,接收并处理 HTML 格式的响应。 我们需要解析 HTML 并提取必要的信息。
然而,现代网页积极使用 JavaScript,并且内容在许多页面上动态加载或形成。 仅仅从 Web 服务器获得响应是不够的,因为它可能只是一个包含大量 JavaScript 的引导页面,执行这些页面会生成必要的内容。
如何使用网络浏览器功能?
使用网络浏览器收集数据怎么样? 它将消除向 Web 服务器发送请求的方法的许多限制。 毕竟,您需要登录某些网站并在页面上执行多项操作才能获得结果。 在某些地方,如果我们能够控制浏览器的用户代理,那将是最好的,这样服务器就不会认为我们是机器人。 它还有助于接收面向桌面的内容,而不仅仅是移动设备的一些精简版本。
在本文中,我们将了解使用网络浏览器的功能收集数据的方法。 特别是,我们会收集指定网站上的所有链接,并检查其中是否存在损坏的链接,即因任何原因导致页面不可用的链接。 我们将通过 JxBrowser 库使用 Chromium 浏览器的功能来完成此操作。
JxBrowser 是一个商业 Java 库,允许您在商业 Java 应用程序中使用 Chromium 的强大功能。 对于开发和销售使用 Java 技术创建的软件解决方案的公司,或者需要为满足内部需求而创建的 Java 应用程序使用先进且可靠的 Web 浏览器组件的公司来说,它非常有帮助。
开始之前你应该做什么?
在开始设计解决方案和编写代码之前我们应该考虑哪些要点? 我们需要从网站的特定页面开始。 它可以是主页或只是网站地址。
在该页面上,我们应该找到其他页面的链接。 链接可能会指向其他网站(外部)和同一网站页面(内部)。 此外,链接并不总是指向另一个页面。 其中一些将访问者带到同一页面的某个部分(此类链接通常以#开头)。 其中一些本身不是链接,而是通过电子邮件发送操作快捷方式 - mailto:。
由于链接可能是循环的,所以我们需要特别小心。 为了正确处理循环引用,我们需要记住已经访问过的页面。
检查链接指向的页面是否不可用也很重要,并且希望获得一个错误代码来解释为什么它无法访问。
使用 JxBrowser 增强您的抓取能力!
算法
考虑到上述所有信息,让我们尝试考虑一下基于网络浏览器的程序如何工作。
- 启动网络浏览器。
- 加载必要的网页。
- 如果页面已加载,则访问其 DOM 并查找所有锚定 HTML 元素。 对于每个组件,获取每个组件的 HREF 值。 这样,我们就可以获得页面上的所有链接。
- 如果页面未加载,请记住该页面的网络服务器错误。
- 记住已处理的页面。
- 如果页面属于我们的网站,则过滤链接; 删除那些我们不感兴趣的内容,例如指向页面子部分或 mailto: 的链接。
- 浏览收到的链接列表。
- 对于列表中的每个页面,请按照从第 11 页开始的步骤进行操作。 #1.
- 如果是外部页面,则记住它但不要分析其链接。 我们只对我们网站页面上的链接感兴趣。
- 处理完所有发现的页面后,我们就完成了导航。
- 关闭网络浏览器。
- 浏览所有已分析的页面并找到那些存在损坏链接的页面。
下面以流程图的形式给出程序的算法。

执行
让我们看看如何实现主要阶段。
启动网络浏览器:

加载网页:

获取 DOM 访问并搜索链接:
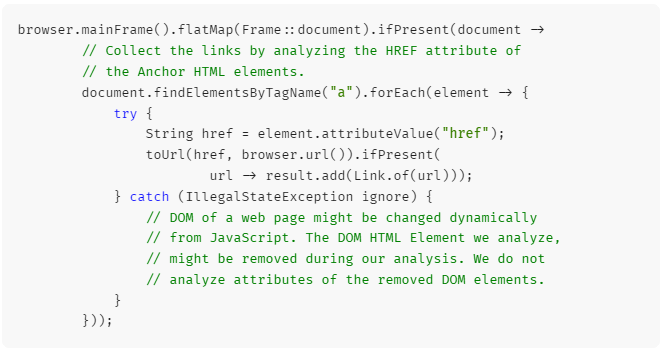
获取 HTML 页面:

分析网站的领先类的示例。



完整的程序代码可以在 GitHub 上找到。
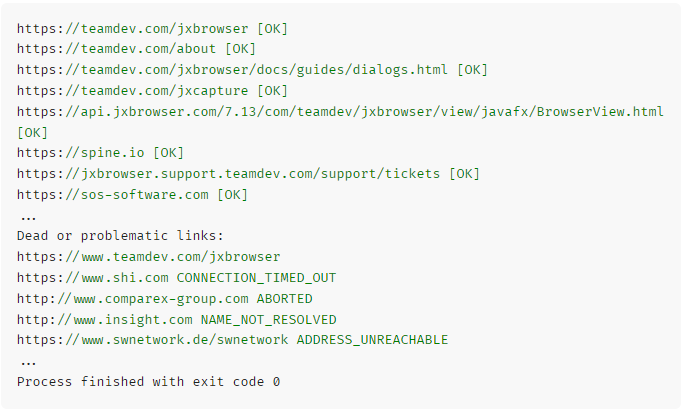
结果
如果我们编译并运行该程序,我们应该得到以下输出:
细微差别、问题和解决方案
以下是在各个网站上实施和测试该解决方案期间遇到的一些细微差别。
许多 Web 服务器都受到 DDoS 攻击的保护,并且频繁的请求会被拒绝并显示错误代码 ABORTED。 要消除网站的负载并进行“礼貌”的分析,您需要使用超时。 在程序中,我们使用了500毫秒的延迟。 不幸的是,即使有这样的延迟,网络服务器仍然拒绝我们的请求。
我们不放弃并尝试以不同的时间间隔加载页面:

Web 服务器可以在加载页面时进行重定向。 当我们加载一个地址时,我们会到达另一个地址。 我们可以记住这两个地址,但重要的是不要只记住应用程序中请求的地址。
Web 服务器可能根本不响应某些请求。 因此,在加载页面时,我们需要利用超时来等待下载。 如果在此超时期间未加载页面,您会将该页面标记为不可用,并显示错误 CONNECTION_TIMED_OUT。
在某些网页上,DOM 模型可能会在页面加载后立即更改。 因此,在分析DOM模型时,我们必须处理某些DOM元素可能没有遍历到DOM树的情况。
结论
您可以使用 Web 浏览器创建 Java Crawler,根据我们的经验,这是一种更自然的网站通信方式。 专业软件市场上的许多SEO蜘蛛和网络爬虫工具多年来已经在使用这些基于网络浏览器功能的业务驱动解决方案,证明了这种方法的有效性。
您可以尝试并尝试新的程序。 从 GitHub 下载源代码,进行编辑以满足您的需求。
如果您对此方法有任何疑问,请在下面发表评论。 我很乐意详细回答您的所有问题。